Spark Apache (Framework Big Data)
Présentation
 Apache Spark exécute en une seule fois la totalité des opérations d'analyse de données en mémoire et en quasi-temps réel. Spark peut être jusqu'à 100 plus rapide que MapReduce pour l'analyse en mémoire. C'est la solution de fait pour l'analyse en streaming (capteurs, campagnes de marketing en temps-réel, recommandations, analyse de sentiments, surveillance des logs...)
Apache Spark exécute en une seule fois la totalité des opérations d'analyse de données en mémoire et en quasi-temps réel. Spark peut être jusqu'à 100 plus rapide que MapReduce pour l'analyse en mémoire. C'est la solution de fait pour l'analyse en streaming (capteurs, campagnes de marketing en temps-réel, recommandations, analyse de sentiments, surveillance des logs...)
Apache Spark is a fast, in-memory data processing engine with elegant and expressive development APIs to allow data workers to efficiently execute streaming, machine learning or SQL workloads that require fast iterative access to datasets. With Spark running on Apache Hadoop YARN, developers everywhere can now create applications to exploit Spark’s power, derive insights, and enrich their data science workloads within a single, shared dataset in Hadoop. The Hadoop YARN-based architecture provides the foundation that enables Spark and other applications to share a common cluster and dataset while ensuring consistent levels of service and response. Spark is now one of many data access engines that work with YARN in HDP.
Apache Spark consists of Spark Core and a set of libraries. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development.
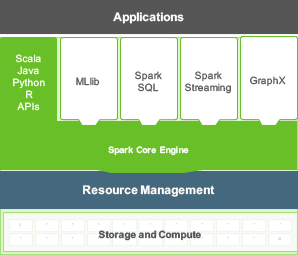
Additional libraries, built atop the core, allow diverse workloads for streaming, SQL, and machine learning.
Spark is designed for data science and its abstraction makes data science easier. Data scientists commonly use machine learning – a set of techniques and algorithms that can learn from data. These algorithms are often iterative, and Spark’s ability to cache the dataset in memory greatly speeds up such iterative data processing, making Spark an ideal processing engine for implementing such algorithms.
Spark also includes MLlib, a library that provides a growing set of machine algorithms for common data science techniques: Classification, Regression, Collaborative Filtering, Clustering and Dimensionality Reduction.
Spark’s ML Pipeline API is a high level abstraction to model an entire data science workflow. The ML pipeline package in Spark models a typical machine learning workflow and provides abstractions like Transformer, Estimator, Pipeline & Parameters. This is an abstraction layer that makes data scientists more productive